For the last fifteen years, the tech world’s mantra was simple: “Move everything to the cloud.” We migrated our servers, our databases, and our logic into the massive, centralized data centers of AWS, Azure, and Google Cloud. But in 2026, we are witnessing a tectonic shift in the opposite direction. According to the 2026 State of the Edge report by IDC, over 75% of enterprise-generated data is now being processed outside of traditional centralized data centers.
The era of the “Cloud Monolith” is ending. We have reached the limits of physics. As we demand real-time responses from autonomous vehicles, instant surgical precision in remote healthcare, and high-velocity AI agents on our smartphones, the millisecond delays caused by sending data to a server three states away are no longer acceptable.
The future isn’t in a far-off server farm; it’s at the “Edge.” If you are a CTO, developer, or business leader, understanding this move from centralized cloud computing to decentralized edge architecture isn’t just a trend—it’s a survival requirement.
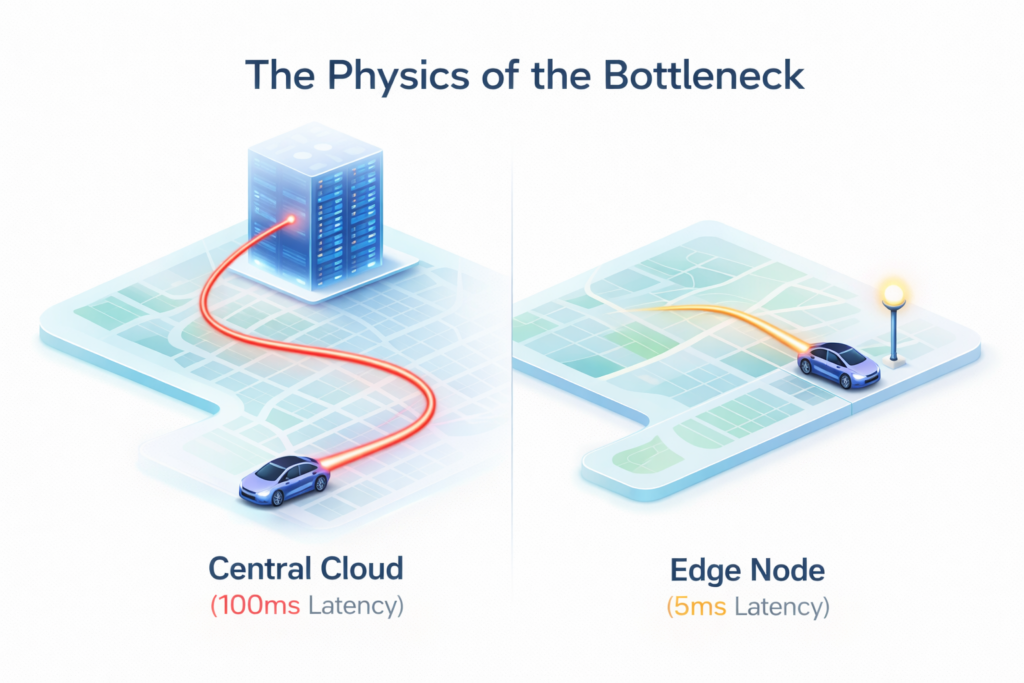
1. The Physics of the Bottleneck: Why Centralized Cloud is Falling Behind
In the early 2020s, a 100ms latency was considered “fast enough.” In 2026, that same latency is a disaster. When a self-driving car needs to decide whether to brake in a split second, it cannot wait for a “handshake” with a cloud server in Virginia.
Centralized cloud computing works on a Hub-and-Spoke model. All data (the spokes) travels to the center (the hub) to be processed, and then the result is sent back. While this is great for storing huge archives of data, it creates two massive problems in our modern world: Latency and Congestion.
As 5G and Wi-Fi 7 become ubiquitous, the amount of data we generate has exploded. If every smart camera, industrial sensor, and wearable device tries to stream raw data to Azure or AWS simultaneously, the global bandwidth “pipes” would simply burst. We have reached a point where it is cheaper and faster to bring the compute to the data, rather than the data to the compute.
2. Speed, Savings, and Security: The 4 Critical Edge Computing Benefits
When businesses ask Google about “the shift to the edge,” they are looking for ROI. In 2026, the transition isn’t just a technical preference; it’s driven by four undeniable edge computing benefits that the centralized cloud simply cannot match.
I. Near-Zero Latency
The most immediate of all edge computing benefits is speed. By processing data on a gateway device or a local micro-data center located mere meters away from the user, latency is reduced to sub-10 milliseconds. For gaming, augmented reality (AR), and automated manufacturing, this difference is the boundary between a seamless experience and total system failure.
II. Drastic Bandwidth Cost Reduction
Cloud providers often charge for “egress”—moving data out of their systems. But the hidden cost is moving data in. By filtering and processing data at the edge, organizations only send the “summary” or the “alert” to the central cloud. For an industrial plant with 5,000 sensors, this can reduce cloud storage and bandwidth costs by up to 90%.
III. Data Sovereignty and Privacy
In an era of hyper-regulation (GDPR 2.0 and the AI Act of 2025), sending sensitive user data across borders is a legal minefield. Edge computing allows companies to keep sensitive data on-site. If a facial recognition system processes your identity locally and only sends a “Verified: Yes” signal to the cloud, your actual biometric data never leaves the device.
IV. Enhanced Reliability (Offline Capability)
Centralized cloud requires a persistent internet connection. Edge computing provides “local survivability.” A smart warehouse running on an edge cluster will continue to operate even if the main internet fiber line is cut. This resilience is why the edge is becoming the standard for critical infrastructure.
3. From AI Models to AI Agents: The 2026 Shift in Edge Logic
In 2024, if you wanted to run an AI query, you sent it to OpenAI’s servers. In 2026, we have seen the rise of Local AI Orchestration. Thanks to the massive power of NPUs (Neural Processing Units) in modern laptops and mobile chips, the “Logic” is moving to the edge.
We are seeing a move from “Request/Response” AI to “Agentic” AI that lives on your device. This is a crucial evolution in Cloud Computing Trends. Instead of one giant model in the cloud, we use “Small Language Models” (SLMs) running on local edge nodes. These agents can perceive, reason, and act in real-time without ever needing an “Internet connection required” warning.
This isn’t just about consumer gadgets; in “Industrial Edge AI,” sensors are now smart enough to detect the sound of a bearing failing in a turbine and shut down the machine in microseconds—a feat impossible for a centralized cloud system due to the transit time of the audio data.
4. The End of AWS/Azure? Not Exactly—Enter the “Hybrid Continuum”
If you’re reading this and thinking about selling your Amazon or Microsoft stock, hold your breath. The transition to the edge isn’t the death of AWS or Azure; it’s their transformation.
AWS (with Outposts and Wavelength), Microsoft (with Azure Stack), and Google (with Google Distributed Cloud) are all aggressively moving their hardware into the edge. We are moving toward a Hybrid Continuum.
- The Edge: For real-time action, data filtering, and private processing.
- The Cloud: For long-term storage, “Heavy” training of AI models, and massive data analytics that aren’t time-sensitive.
Search intent for developers is increasingly focused on “How to orchestrate across cloud and edge?” The answer in 2026 is Kubernetes at the Edge (K3s). We are no longer writing code for a specific server; we are writing “cloud-native” apps that can seamlessly float between a massive data center and a small edge gateway based on where the compute is needed most at that specific moment.
5. Implementation Hurdles: What Google and Searchers are Asking
Despite the massive edge computing benefits, the transition is difficult. The questions most searched on Google regarding edge implementation in 2026 are:
- “How do I manage security on 10,000 edge devices?” (Answer: Zero Trust Architecture and automated “fencing”).
- “Is edge computing more expensive to set up?” (Answer: The CapEx is higher for hardware, but the OpEx in bandwidth and cloud fees is drastically lower).
- “Does edge work for small businesses?” (Answer: Yes, especially with the rise of “Edge-as-a-Service” providers who manage the hardware for you).
For businesses to win in this new era, they must stop viewing the cloud as a “place” and start viewing it as a “capability” that should exist wherever the user is standing.
Key Takeaways
- Physics Wins: Latency and bandwidth bottlenecks are forcing data processing to move closer to the source.
- Edge is the Real-Time Layer: For AI agents, autonomous systems, and AR, the edge is the only viable infrastructure.
- Efficiency Drives ROI: One of the greatest edge computing benefits is the massive reduction in data transit and storage costs.
- Privacy is Built-In: Edge computing is the premier solution for data sovereignty and regulatory compliance.
- The Cloud is Still Vital: Centralized cloud remains the “Library” and the “Classroom” where models are trained and data is archived, while the Edge is the “Field” where actions happen.