
If you’ve tried deploying a vanilla Large Language Model (LLM) for your company, you’ve likely hit a wall. Whether it’s ChatGPT or Llama 3, general-purpose models suffer from a fundamental flaw in an enterprise setting: they don’t know your secrets. They have no access to your 2025 financial projections, your proprietary engineering diagrams, or your specific customer service playbooks.
According to a recent 2025 study by McKinsey & Company, while 72% of organizations have adopted AI, only 15% have successfully moved beyond general use cases into “specialized domain expertise.” The primary culprit? Hallucinations. Models would rather lie than admit they don’t have your internal data.
This is where RAG (Retrieval-Augmented Generation) changes the game. It allows you to ground an AI’s intelligence in the specific, private, and real-time truth of your enterprise. In this RAG AI Tutorial, we’re going deep into the architecture, the implementation, and the strategic edge that turns a chatbot into an enterprise “brain.”
1. RAG vs. Fine-Tuning: Why “Retrieval” is the New Enterprise Standard
The most common question Google receives is: “Should I fine-tune my model or use RAG?”
For years, we were told that to “teach” an AI about your company, you needed to fine-tune it—essentially retraining the model on your data. In 2026, we know that fine-tuning for knowledge is a fool’s errand. Why?
- Static Knowledge: The moment you finish fine-tuning, your data is outdated.
- High Cost: Fine-tuning requires massive GPU compute cycles.
- Opaque Logic: You can’t easily see why a fine-tuned model gave a specific answer.
RAG is different. Instead of baking your data into the model’s weights, RAG treats the LLM like an open-book student. When a question is asked, the system looks up the answer in your “textbook” (your internal docs) and asks the AI to summarize it. It’s faster, allows for citation of sources, and costs roughly 90% less than training cycles.
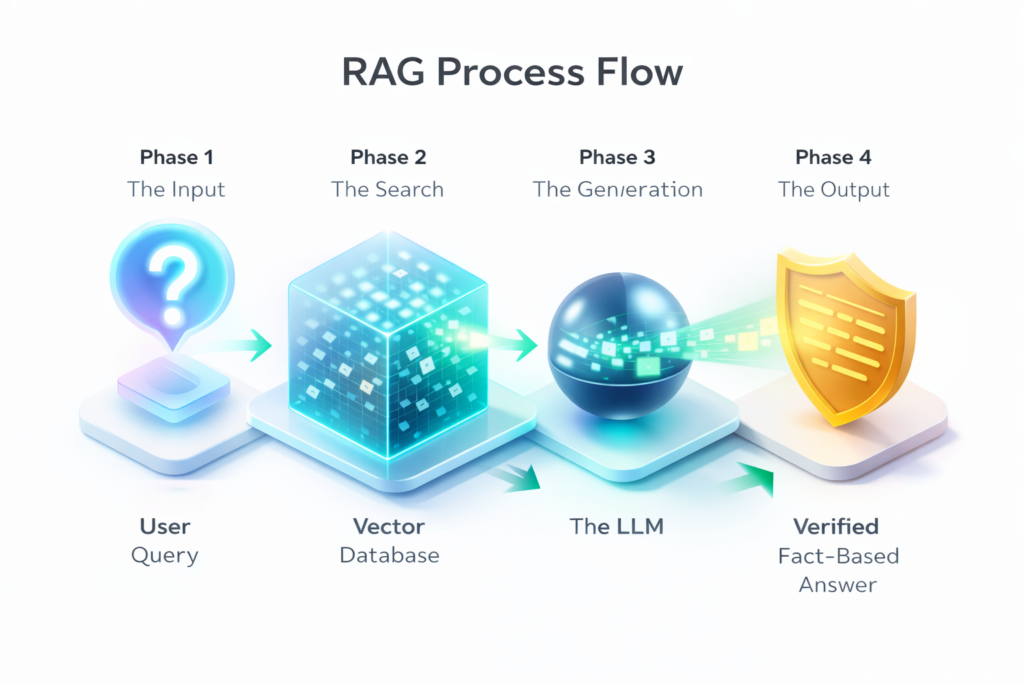
2. The Core Architecture: How the RAG Pipeline Functions
To follow this RAG AI Tutorial at an enterprise scale, you must understand the four distinct layers of the pipeline. In 2026, we call this the “Semantic Bridge.”
A. The Knowledge Base (The Raw Fuel)
Your enterprise data lives in silos—SharePoint, Jira, PDFs, and SQL databases. The first step is “ingestion.” In this phase, unstructured data is converted into clean text.
B. Vector Embeddings (The Digital DNA)
Computers don’t read words; they read numbers. An “embedding model” takes a paragraph of your data and turns it into a high-dimensional vector—essentially a string of numbers that represents its meaning. For example, the sentence “We offer a 30-day refund policy” and “Customers have one month to return items” will have very similar vector coordinates because they mean the same thing.
C. The Vector Database (The Filing Cabinet)
This is where the magic happens. Standard databases look for exact keyword matches. A Vector Database (like Pinecone, Weaviate, or Milvus) looks for semantic proximity. This is the core engine of your RAG system, allowing the AI to find the right information even if the user uses the wrong keywords.
D. The LLM Generator (The Brain)
Finally, the “Top-K” most relevant snippets are retrieved and fed into an LLM (like GPT-4o or Llama 3) with a specific instruction: “Use ONLY these snippets to answer the user’s question. If the answer isn’t here, say you don’t know.”
3. The RAG AI Tutorial: 5 Steps to Implementation
If you’re ready to build, here is the technical blueprint used by high-performance engineering teams in 2026.
Step 1: Chunking Strategy
Don’t just feed the AI an entire 200-page manual at once. It will get “lost in the middle.” Break your data into “chunks” of 500–1,000 tokens. Pro-tip: Use “sliding window chunking” where chunks overlap slightly. This ensures that the context at the end of one chunk isn’t lost in the start of the next.
Step 2: Selecting an Embedding Model
While everyone focuses on the LLM, the embedding model is actually more important for RAG. Use specialized models like Cohere’s Embed v3 or Voyage AI, which are optimized for enterprise-style document retrieval.
Step 3: Setting Up the Vector Store
In 2026, enterprises are moving away from managed clouds and toward hybrid solutions. Set up your vector database with “Metadata Filtering.” This allows the AI to filter results by department (e.g., “Only look in HR docs for this question”) which drastically increases accuracy.
Step 4: Hybrid Search Integration
Pure semantic search is sometimes “too fuzzy.” The best RAG systems use Hybrid Search, combining old-school keyword matching (BM25) with vector search. This ensures that specific part numbers or names are found precisely, while conceptual questions are handled semantically.
Step 5: Post-Retrieval Re-Ranking
Once you pull the top 10 chunks from your database, use a Re-ranker. A re-ranker is a specialized AI that takes a final look at those 10 snippets and puts the most relevant ones at the very top of the prompt. This reduces hallucinations by 60–80%.
4. Addressing Search Intent: Solving the “Enterprise Fear”
The primary “Search Intent” for IT leaders is security. If you connect an AI to your enterprise data, how do you keep it safe?
- Role-Based Access Control (RBAC): Your RAG system should check user permissions before it retrieves data. An intern shouldn’t be able to “ask” the AI about the CEO’s salary just because the data is in the vector store.
- PII Masking: Implement a layer that automatically detects and masks Personally Identifiable Information (social security numbers, phone numbers) before it ever leaves your secure environment.
- The Hallucination Filter: In 2026, we use “Reflexive RAG.” Before the AI answers the user, it asks itself: “Is this answer supported by the citations?” If the answer is “no,” the response is blocked.
5. Multimodal RAG: The Future of Enterprise Data
As we look toward the end of 2026, the RAG AI Tutorial is expanding. We are no longer limited to text.
Modern Multimodal RAG allows your employees to ask questions about visual data. Imagine a technician taking a photo of a broken machine part. The RAG system retrieves the CAD diagrams (Visual RAG), reads the repair logs (Text RAG), and generates a step-by-step repair guide with an overlay on the technician’s AR glasses. This isn’t science fiction; this is the logical progression of retrieval-based intelligence.
Key Takeaways
- Accuracy Over Intelligence: RAG is about providing an “open-book” to the LLM to prevent hallucinations.
- Architecture Matters: A successful RAG pipeline requires a robust ingestion, chunking, and re-ranking strategy.
- Search Proximity: Vector databases are the “filing cabinets” that allow AI to understand the meaning of your documents, not just the keywords.
- Security First: Enterprise RAG must be built with Role-Based Access Control and PII filtering from day one.
- Citations are the Goal: The value of RAG lies in the AI saying, “Based on page 4 of the Q3 Policy…” rather than simply guessing.
Leave a Reply