
If you are still relying solely on public, “off-the-shelf” AI models to power your business operations, you are already falling behind. According to a recent 2025 IDC Worldwide Perspective, over 75% of Global 2000 companies have now transitioned from using public AI APIs to deploying Custom Large Language Models specifically tailored to their proprietary data.
The era of “generic AI” is fading. While tools like ChatGPT and Claude are incredible for general tasks, they lack the one thing that makes your business valuable: your unique intellectual property, your specific brand voice, and your private operational data. In 2026, a custom model isn’t just a luxury for Big Tech—it is the defensive moat that prevents your competitors from out-innovating you.
But why is this shift happening so rapidly, and more importantly, how can your organization build its own “private brain” without a billion-dollar research budget?
1. Why Public AI Isn’t Enough: The Strategic Case for Custom Large Language Models
In the early days of the AI boom, businesses were happy to “plug and play.” However, as the technology matured, three major pain points emerged that only Custom Large Language Models can solve.
Data Sovereignty and Security
When you feed sensitive information into a public model, you are essentially training your competitor’s future assistant. High-profile data leaks at major tech firms in the past few years have proven that “Enterprise Privacy” tiers often aren’t enough for regulated industries like finance, healthcare, or defense. A custom model, hosted on your own virtual private cloud (VPC), ensures that your data never leaves your perimeter.
Elimination of the “Generic Response” Problem
Generic models are trained on the “average” of the internet. This means their advice is often mediocre. If you are a specialized engineering firm or a legal practice, a generic LLM doesn’t understand your specific jargon, your past project history, or your unique methodology. Customization allows the AI to think like your top-performing senior partner, not a high-school student.
Cost Predictability at Scale
While a $20/month subscription seems cheap, API costs for high-volume enterprise applications can skyrocket. For organizations processing millions of tokens daily, running a distilled, quantized custom model on their own hardware is often 60-70% more cost-effective over a three-year horizon.
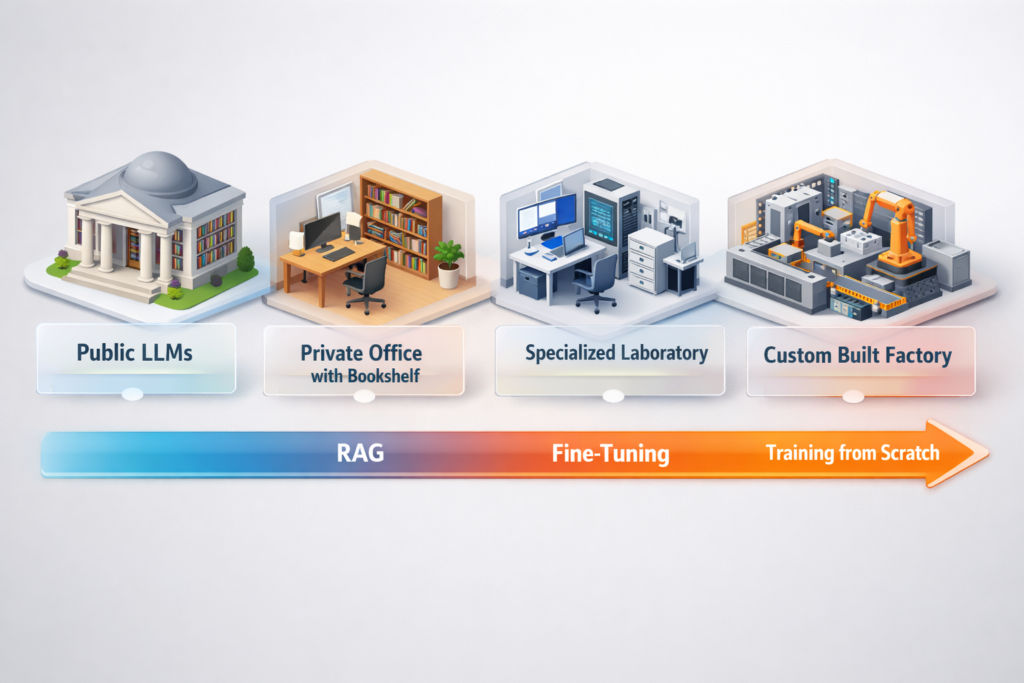
2. Build vs. Buy: Decoding the Customization Spectrum
The most common question Google sees regarding this topic is: “Do I need to build an LLM from scratch?” The answer is almost always no. Building a custom model in 2026 follows a spectrum of complexity and cost.
Retrieval-Augmented Generation (RAG): The “Open Book” Approach
RAG is the most popular way to create a custom experience. Instead of changing the model itself, you provide it with a “library” of your company’s documents. When a user asks a question, the system searches your private library and hands the relevant facts to the AI to summarize.
- Best for: Customer support, HR portals, and internal knowledge bases.
Fine-Tuning: The “Specialized Training” Approach
Fine-tuning involves taking a pre-trained base model (like Llama 3 or Mistral) and training it further on a smaller, high-quality dataset of your company’s specific outputs.
- Best for: Adopting a specific brand voice, specialized medical coding, or learning complex proprietary programming languages.
Continued Pre-training: The “Deep Immersion” Approach
This is for companies in highly specialized niches. You take a base model and expose it to massive amounts of raw, domain-specific text (e.g., thousands of chemical patents or maritime laws). This changes the model’s fundamental understanding of the world.
3. The Blueprint: How to Build Your Custom Large Language Model
Building Custom Large Language Models has become significantly more accessible thanks to the “modularization” of the AI stack. Here is the high-level framework for a 2026 deployment.
Step 1: Data Curation (The Most Critical Step)
An AI is only as good as its training data. To build a custom model, you must aggregate your “dark data”—PDFs, Slack logs, old emails, and project databases. In 2026, the gold standard is Synthetic Data Augmentation, where you use a larger model to “clean” and “label” your messy internal data before feeding it to your custom model.
Step 2: Choosing Your Base Model
You don’t need to start with a blank slate. Open-source models have reached parity with many closed-source systems. Depending on your needs, you might choose:
- A “Small” Model (7B-14B parameters): For fast, edge-based tasks like mobile apps.
- A “Large” Model (70B+ parameters): For complex reasoning and deep technical analysis.
Step 3: Infrastructure and Compute
Where will your model live?
- On-Premise: For maximum security (common in government/defense).
- Serverless GPU Providers: Using services like Lambda Labs or RunPod for elastic, cost-effective training.
- Hybrid Cloud: Storing data on-site but using cloud GPUs for the heavy lifting of training.
Step 4: Governance and Red-Teaming
Before deploying, you must “red-team” your model. This means intentionally trying to make it leak data or give biased answers. In 2026, automated governance layers sit on top of the LLM to ensure it adheres to company policy in real-time.
4. Search Intent: Answering Your Burning Questions
“How much does it cost to build a custom LLM?”
While training a model like GPT-4 costs hundreds of millions, fine-tuning a high-performance open-source model for business use typically ranges from $20,000 to $150,000 in 2026. This includes data preparation, compute time, and engineer salaries.
“How long does it take?”
A RAG-based custom solution can be deployed in 2–4 weeks. A fully fine-tuned model tailored to a specific brand voice usually takes 3–5 months to move from data collection to production.
“Do I need a team of Ph.Ds?”
No. The rise of “AI Orchestration” platforms means that a competent team of Full-Stack Engineers and Data Scientists can now deploy Custom Large Language Models using low-code or Python-based frameworks.
5. The ROI: Turning AI into a Profit Center
The businesses winning in 2026 aren’t just using AI to save time; they are using it to generate revenue.
- Hyper-Personalization: A retail brand using a custom model can analyze a customer’s entire purchase history to generate a personal shopping assistant that actually sounds like a stylist, not a robot.
- Institutional Memory: When a veteran employee retires, their “knowledge” stays within the custom model, which has been trained on their reports and decisions for a decade.
- Unmatched Speed: Legal firms are now using custom models to perform “first-pass” contract reviews in seconds, allowing them to take on 5x the client load without increasing headcount.
Key Takeaways
- Move Beyond Generic AI: Public models are for general tasks; Custom Large Language Models are for proprietary competitive advantage.
- Data is Your Fuel: The quality of your internal documentation determines the quality of your AI. Start cleaning your “dark data” today.
- Prioritize Security: Building custom allows you to keep your most valuable intellectual property inside your own secure infrastructure.
- Start with RAG, Move to Fine-Tuning: Most businesses don’t need to train a model from scratch. Start with Retrieval-Augmented Generation for quick wins.
- The Moat of 2026: In an AI-saturated world, the only way to stand out is to have a model that knows things no other AI knows.
Leave a Reply